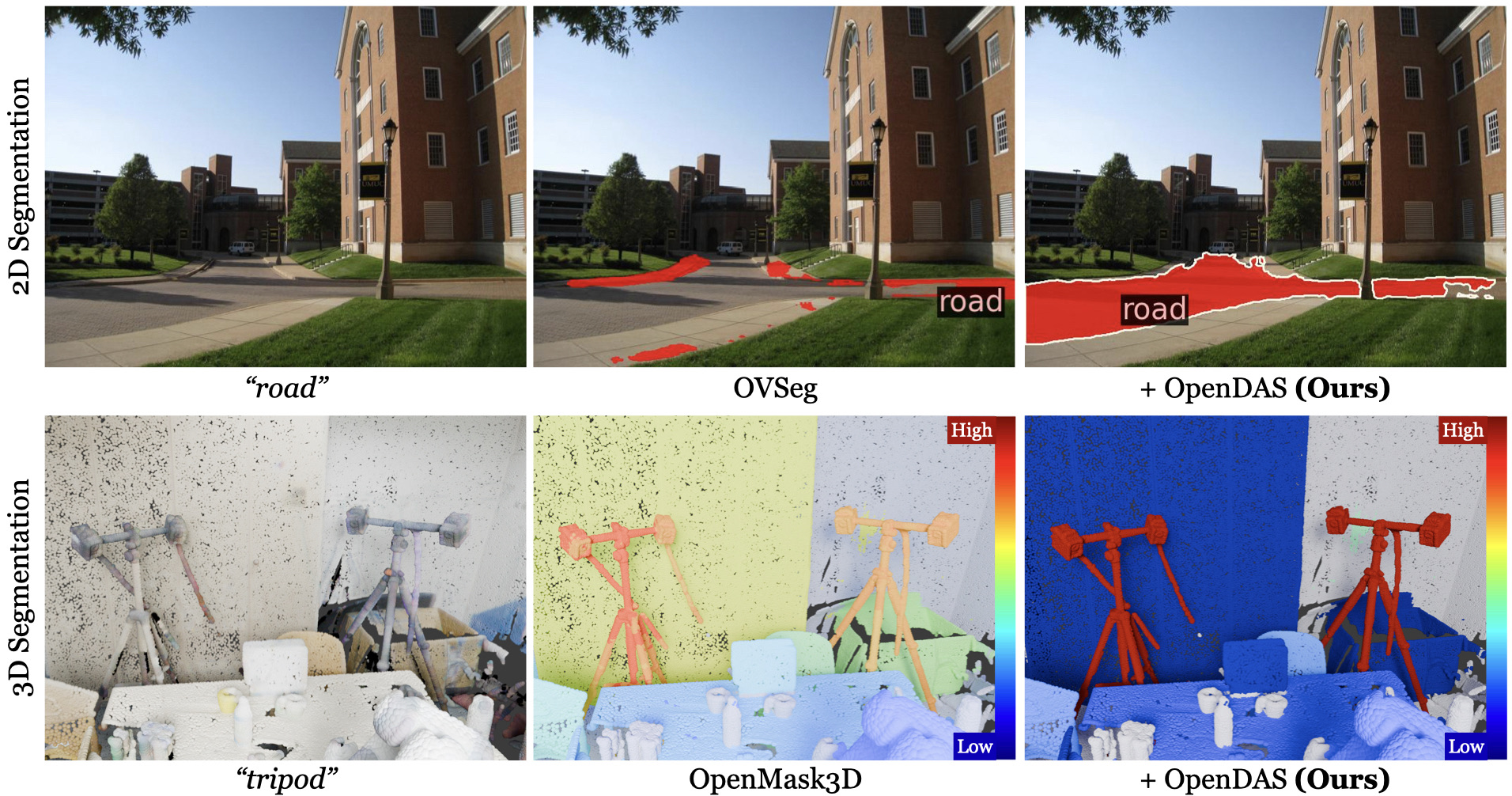
No Adaptation
Recently, Vision-Language Models (VLMs) have advanced segmentation techniques by shifting from the traditional segmentation of a closed-set of predefined object classes to open-vocabulary segmentation (OVS), allowing users to segment novel classes and concepts unseen during training of the segmentation model. However, this flexibility comes with a trade-off: fully-supervised closed-set methods still outperform OVS methods on base classes, that is on classes on which they have been explicitly trained. This is due to the lack of pixel-aligned training masks for VLMs (which are trained on image-caption pairs), and the absence of domain-specific knowledge, such as autonomous driving. Therefore, we propose the task of open-vocabulary domain adaptation to infuse domain-specific knowledge into VLMs while preserving their open-vocabulary nature. By doing so, we achieve improved performance in base and novel classes. Existing VLM adaptation methods improve performance on base (training) queries, but fail to fully preserve the open-set capabilities of VLMs on novel queries. To address this shortcoming, we combine parameter-efficient prompt tuning with a triplet-loss-based training strategy that uses auxiliary negative queries. Notably, our approach is the only parameter-efficient method that consistently surpasses the original VLM on novel classes. Our adapted VLMs can seamlessly be integrated into existing OVS pipelines, e.g., improving OVSeg by +6.0% mIoU on ADE20K for open-vocabulary 2D segmentation, and OpenMask3D by +4.1% AP on ScanNet++ Offices for open-vocabulary 3D instance segmentation without other changes.
No Adaptation
OpenDAS (Ours)

Ground-Truth

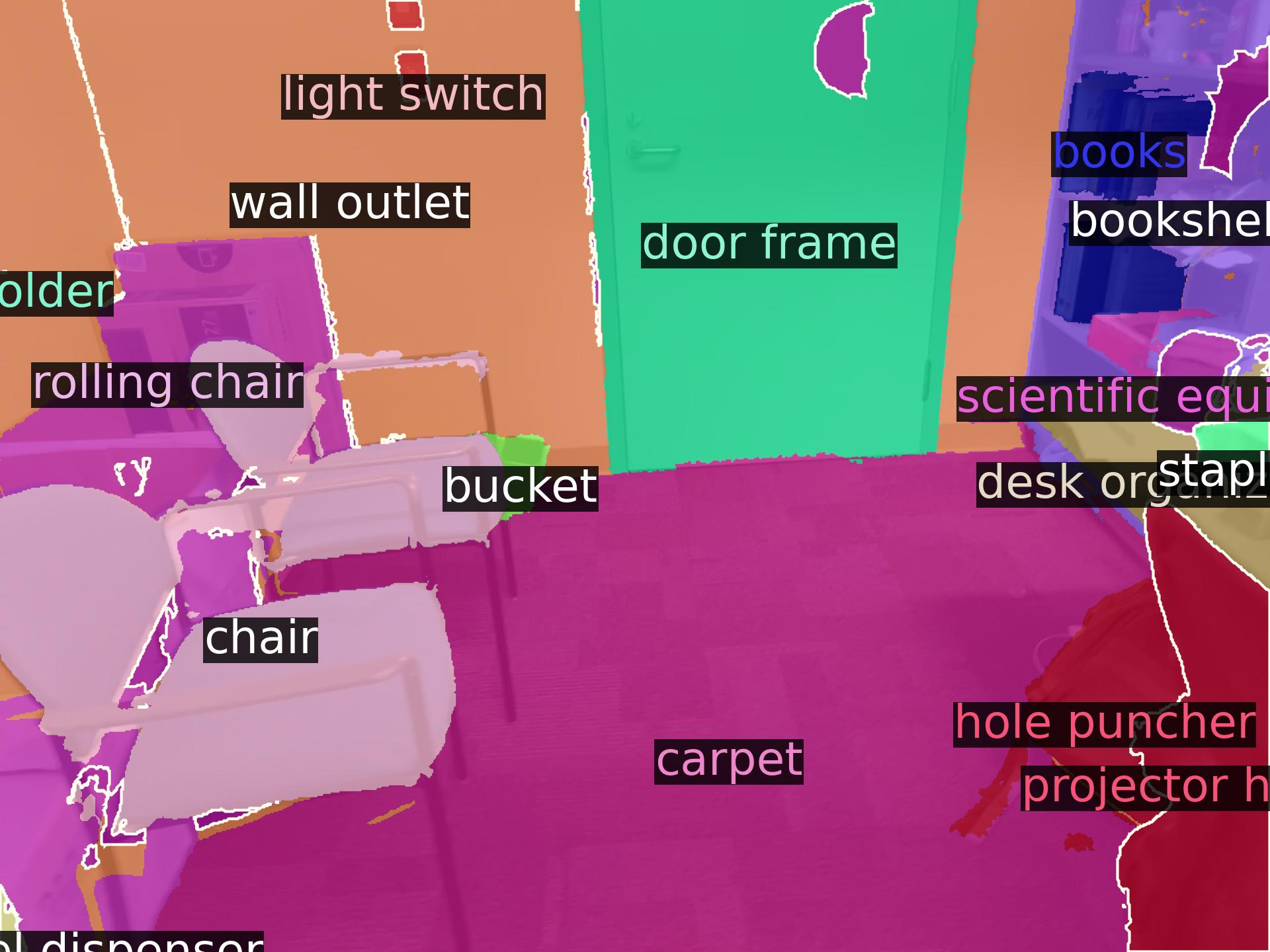
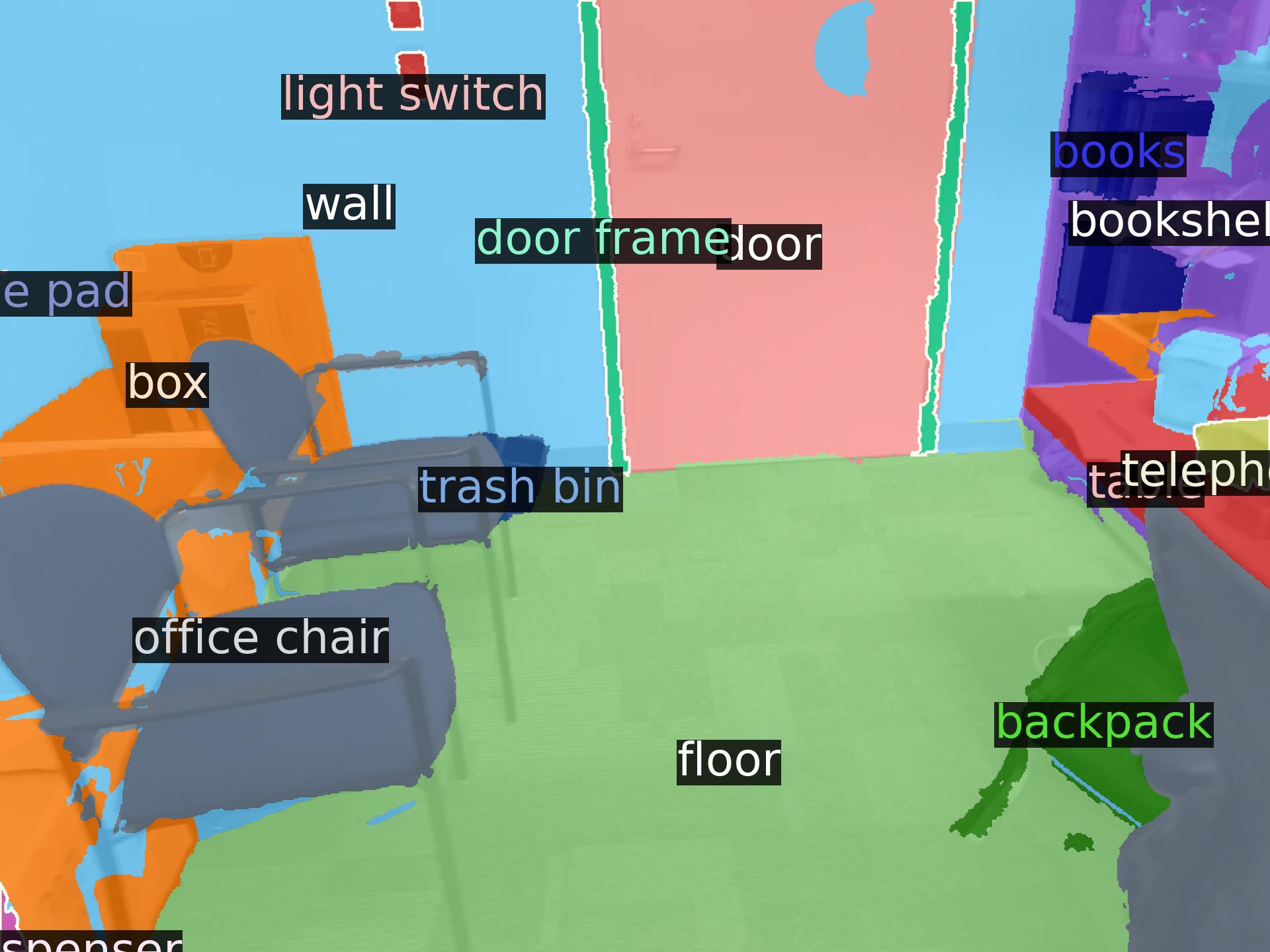
No Adaptation
OpenDAS (Ours)
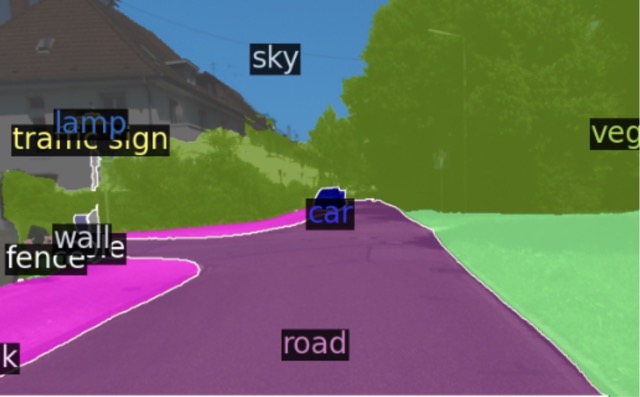
Ground-Truth
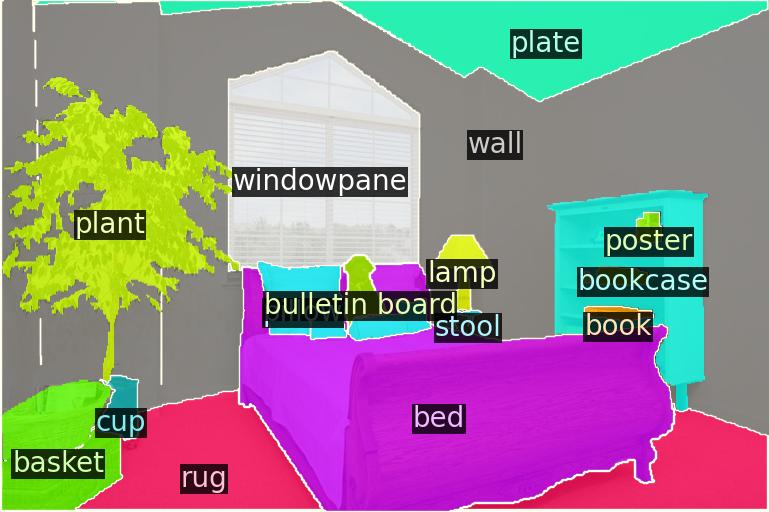
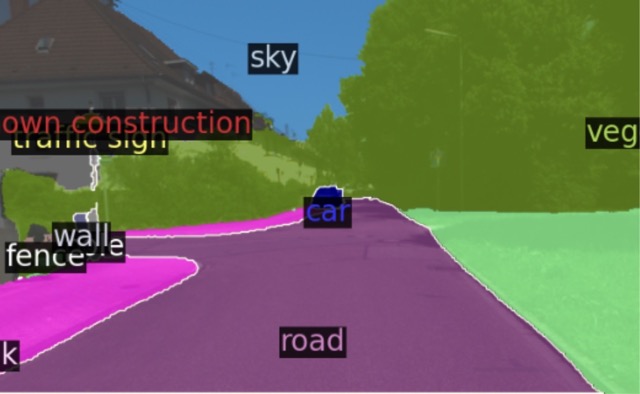
No Adaptation
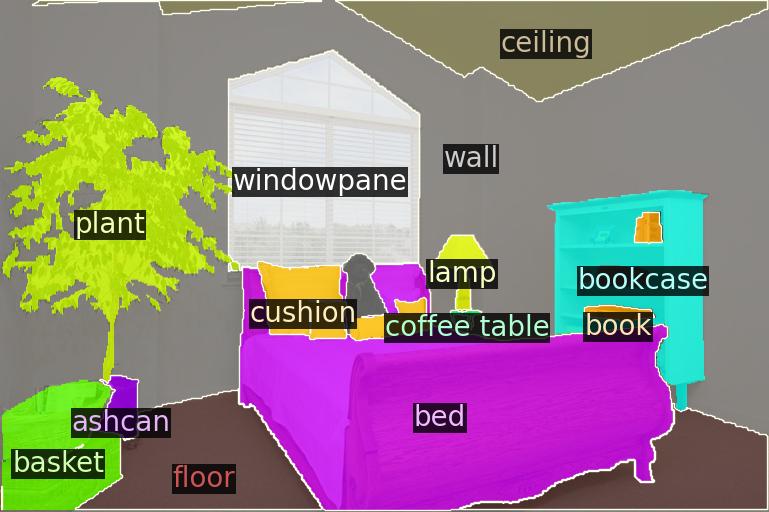
OpenDAS (Ours)
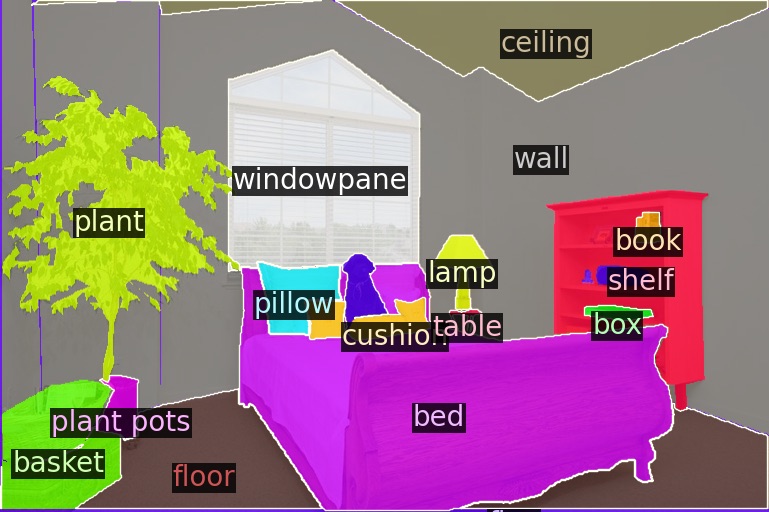
Ground-Truth
We evaluate segment classification over base queries (B-F1) as well as generalization to unseen, novel queries (N-F1) and the overall weighted F1 (W-F1). To be able to test on novel queries, we evaluate on ScanNet++ Offices (SN++) and cross-dataset by adapting to ADE20K-150 (A-150) and testing on SN++ O and KITTI-360 (K-360). Performance degradation compared to the original CLIP baseline is shown in red.
| Method | Modality | # Params | SN++ Offices | A-150 → SN++ O | A-150 → K-360 | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| W-F1 | B-F1 | N-F1 | W-F1 | B-F1 | N-F1 | W-F1 | B-F1 | N-F1 | |||
| No adaptation | 11.2 | 11.0 | 12.0 | 11.2 | 11.3 | 11.0 | 24.1 | 23.0 | 24.9 | ||
| CoCoOp | 📘 | ~77K | 25.7 | 34.3 | 12.7 | 11.2 | 18.0 | 9.9-1.1 | 27.1 | 30.4 | 22.1-2.8 |
| VPT | 🎨 | ~786K | 33.8 | 37.6 | 12.8 | 13.0 | 19.2 | 8.8-2.2 | 29.5 | 34.8 | 25.8 |
| RPO | 🎨 📘 | ~43K | 30.6 | 40.9 | 14.9 | 13.4 | 13.9 | 13.3 | 33.7 | 42.8 | 19.9-5.0 |
| MaPLe | 🎨 📘 | ~18935K | 36.3 | 48.1 | 18.4 | 18.8 | 29.3 | 16.8 | 43.5 | 57.7 | 22.2-2.7 |
| OpenDAS (Ours) | 🎨 📘 | ~233K | 40.2 | 51.5 | 23.0 | 23.0 | 30.4 | 21.6 | 47.1 | 60.8 | 26.6 |

Input

OpenMask3D

+ OpenDAS (Ours)

Input

OpenMask3D

+ OpenDAS (Ours)
@misc{yilmaz2024opendas,
title={OpenDAS: Open-Vocabulary Domain Adaptation for Segmentation},
author={Gonca Yilmaz and Songyou Peng and Marc Pollefeys and Francis Engelmann and Hermann Blum},
year={2024},
eprint={2405.20141},
archivePrefix={arXiv},
primaryClass={cs.CV}
}